5 bytes
5 bytes
1 to 31 bytes
5 bytes
1 to 31 bytes
5 bytes

If you are new to BBC BASIC, or you are experiencing difficulty with files, you might find these notes useful. Some of the concepts and procedures described are quite complicated and require an understanding of file structures. If you have trouble understanding these parts, don't worry. Try the examples and write some programs for yourself and then go back and read the notes again. As you become more comfortable with the fundamentals, the complicated bits become easier.
The programs listed in these notes are included with the supplied example programs. They are provided for demonstration and learning purposes and are not intended to be taken and used as working programs without modification to suit your needs. If you want to, you are free to incorporate any of the code in the programs you write. Use them, change them, or ignore them as you wish. There is only one proviso; the programs have been tested and used a number of times, but we cannot say with certainty that they are bug free. Remember, debugging is the art of taking bugs out - programming is the art of putting them in.
All computers are able to store and retrieve information from a non-volatile medium (in other words, you don't lose the information when the power gets turned off). Audio cassettes were once used for small micro computers, diskettes for medium sized systems and magnetic tape and large disks for big machines. Nowadays, all but the smallest machines incorporate a hard disk or SSD with several gigabytes of storage. In order to be able to find the information you want, the information has to be organised in some way. All the information on one general subject is gathered together into a FILE. Within the file, information on individual items is grouped together into RECORDS.
Life is easier with a computer. There is an index which tells the computer where to look for each of the files and the serial search for the file is not necessary. However, once you have found the file, you still need to read through it to find the record you want.
There are a number of ways to overcome this problem. We will consider the two simplest; random access (or relative) files and indexed files.
What happens when you close an account? You can't tear out the page because that would upset the numbering system. All you can do is draw a line through it - in effect, turn it into a blank page. Before long, quite a number of pages will be 'blank' and a growing proportion of your book is wasted.
With other forms of 'numbering', say by the letters of the alphabet, you could still not guarantee to fill all the pages. You would have to provide room for the Zs, but you may never get one. When you started entering data, most of the pages would be blank and the book would only gradually fill up.
The same happens with this sort of file. A random file which has a lot of empty space in it is described as sparse. Most random files start this way and most never get more than about ¾ full. Count the number of empty 'slots' in your address book and see what proportion this is of the total available.
If we had an index at the front of the book we could scan the index for the name and then turn to the appropriate page. We would still be wasting a lot of space because some names, addresses etc are longer than others and our 'slots' must be large enough to hold the longest.
Suppose we numbered all the character positions in the book and we could easily move to any character position. We could write all the names, addresses, etc, one after the other and our index would tell us the character position for the start of each name and address. There would be no wasted space and we would still be able to turn directly to the required name.
What would happen when we wanted to cancel an entry? We would just delete the name from the index. The entry would stay in its original place in the book, but we would never refer to it. Similarly, if someone changed their address, we would just write the name and the new address immediately after the last entry in the book and change the start position in the index. Every couple of years we would rewrite the address book, leaving out those items not referenced in the index and up-date the index (or write another one).
This is not a practical way to run a paper and pencil address book because it's not possible to turn directly to the 3423rd character in a book, and the saving in space would not be worth the tedium involved. However, with BBC BASIC you can turn to a particular character in a file and it's very fast, so it's well worth doing.
Serial files cannot be used to access particular records from within the file quickly and easily. In order to do this with the minimum access time, random access files are necessary. However, a random file generally occupies more space than a serial file holding the same amount of data because the records must be a fixed length and some of the records will be empty.
Most versions of BASIC only offer serial and random files, but because of the way that files are handled by BBC BASIC it is possible to construct indexed, and even linked, files as well. Indexed files take a little longer to access than random files and it is necessary to have a separate index file, but they are generally the best space/speed compromise for files holding a large amount of data.
Because of the character by character action of the write/read process, it is possible (in fact, necessary) to keep track of your position within the file. BBC BASIC does this for you automatically and provides a pointer PTR (a pseudo-variable) which holds the position of the NEXT character (byte) to be written/read. Every time a character is written/read PTR is incremented by one, but it is possible to set PTR to any number you like. This ability to 'jump around' the file enables you to construct both random (relative) and indexed files.
BBC BASIC provides the facility for completely free-format binary data files. Any file which can be read by the computer, from any source and in any data format, can be processed using the BGET, BPUT and PTR functions.
Apart from the speed increase, file buffering should be transparent to the user and, unless you are doing something unconventional, you can forget about it. It is worth noting that using the PTR#file_num= statement has the side-effect of flushing the appropriate BBC BASIC file buffer.
If an attempt to open a file fails because of a sharing violation, the OPENOUT or OPENUP call will return the value zero. In the case of OPENUP this is the same value which is returned if the file is not found; you can distinguish between the two cases by attempting to open the file with OPENIN. If that succeeds, the problem must have been a sharing violation.
Windows™ accepts a composite file name (file specification) in the following format:
The drivename is a single letter followed by a colon and denotes the disk (or other) drive on which the file will be found or created, e.g. C:DRIVENAME\PATHNAME\FILENAME.EXTension
The pathname is the name of the directory or the path to the directory (folder) in which the file will be found or created. Directories are separated by the backslash character, e.g. WINDOWS\SYSTEM
The filename and optional extension identify a single file within the directory (folder). Whenever a filename without an extension is given, BBC BASIC will append .BBC as the default extension. If you want to maintain compatibility with MS-DOS™ you should restrict filenames to eight characters or fewer and extensions to three characters or fewer; you should also use only capital letters and numbers.
OPENIN OPENUP OPENOUT EXT# PTR# INPUT# BGET# GET$ PRINT# BPUT# CLOSE# END EOF#
When you open the file, a channel number (an integer number) is returned by the interpreter and you will need to store it for future use. The open commands are, in fact, functions which open the appropriate file and return its channel number.
You use the channel number for all subsequent access to the file (with the exception of the Operating System commands).
If the system has been unable to open the file, the channel number returned will be 0. This will occur if you try to open a non-existent file for input (OPENIN or OPENUP) or a read-only file for output (OPENOUT or OPENUP) or whenever the file cannot be opened for another reason.
You always need to store the channel number because it must be used for all the other file statements and functions. If you choose a variable with the same name as the file, you will make programs which use a number of files easier to understand:file_num = OPENOUT "PHONENUMS.DAT"
phonenums=OPENOUT "PHONENUMS.DAT" opfile=OPENOUT opfile$
OPENIN will fail (channel number returned = 0) if the file does not already exist.address=OPENIN "ADDRESS.DAT" check_file=OPENIN check_file$
If you try to write to a file opened with OPENIN you will get an 'Access denied' error (error number 189).
A file may be opened any number of times with OPENIN, but only once with OPENUP or OPENOUT. See the sub-section Networking - shared files for more details.
OPENUP will fail (channel number returned = 0) if the file does not already exist.address=OPENUP "ADDRESS.DAT" check_file=OPENUP check_file$
A file may be opened once with OPENUP and any number of times with OPENIN. See the earlier sub-section Networking - Shared Files for more details.
CLOSE#fnum CLOSE#0
For this to work correctly the data must have been written with a PRINT# statement. READ# can be used as an alternative to INPUT#INPUT#data,name$,age,height,sex$
PRINT#data,name$,age,height,sex$
EXT# can also be used to change the length of a file:length = EXT#fnum
EXT#fnum = newlength
When the file is OPENED, PTR# is set to zero. However, you can set PTR# to any value you like (even beyond the end of the file - so take care).oldptr = PTR#fnum PTR#fnum = newptr
Reading or writing, using INPUT# and PRINT#, (and BGET# and BPUT# - explained later), takes place at the current position of the pointer. The pointer is automatically updated following a read or write operation.
A file opened with OPENUP may be extended by setting PTR# to its end (PTR# = EXT#), and then writing the new data to it. You must remember to CLOSE such a file in order to update its directory entry with its new length. A couple of examples of this are included in the sections on serial and indexed files.
Using a 'PTR#fnum=' statement will flush the appropriate BBC BASIC file buffer. This can be useful when you need to ensure that the data has actually been written to the storage medium (or sent to a remote device).
Attempting to read beyond the current end of file will not give rise to an error. Either zero or a null string will be returned depending on the type of variable read.eof=EOF#fnum
EOF# is only really of use when dealing with serial (sequential) files. It indicates that PTR# is greater than the recorded length of the file (found by using EXT#). When reading a serial file, EOF# would go true when the last byte of the file had been read.
EOF# will NOT be true if an attempt has been made to read from an empty area of a sparse random access file. Reading from an empty area of a sparse file will return garbage. Because of this, it is difficult to tell which records of an uninitialised random access file have had data written to them and which are empty. These files need to be initialised and the unused records marked as empty.
or, more expedientlybyte=BGET#fnum char$=CHR$(byte)
char$=CHR$(BGET#fnum)
BPUT#fnum,&1B BPUT#fnum,house_num BPUT#fnum,ASC "E"
You may notice that we have cheated a little in that a procedure is called to close the files and end the program without returning. This saves using a GOTO, but leaves the return address on the stack. However, ending a program clears the stack and no harm is done. You should not use this sort of trick anywhere else in a program. If you do you will quickly use up memory.
REM F-WSER1 : REM EXAMPLE OF WRITING TO A SERIAL CHARACTER DATA FILE : REM This program opens a data file and writes serial REM character data to it. The use of OPENOUT ensures that, REM even if the file existed before, it is cleared before REM being written to. : OSCLI "CD """+@usr$+"""" : phonenos=OPENOUT "PHONENOS.DAT" PRINT "File Name PHONENOS.DAT Opened as Channel ";phonenos PRINT REPEAT INPUT "Name ? " name$ IF name$="" THEN PROC_end INPUT "Phone Number ? " phone$ PRINT PRINT#phonenos,name$,phone$ UNTIL FALSE : DEF PROC_end CLOSE#phonenos END
REM F-RSER1 : REM EXAMPLE OF READING A SERIAL CHARACTER FILE : REM This program opens a previously written serial file REM and reads it. : OSCLI "CD """+@usr$+"""" : phonenos=OPENIN "PHONENOS.DAT" PRINT "File Name PHONENOS.DAT Opened as Channel ";phonenos PRINT REPEAT INPUT#phonenos,name$,phone$ PRINT name$,phone$ UNTIL EOF#phonenos : CLOSE#phonenos END
REM F-WESER1
:
REM EXAMPLE OF WRITING TO THE END OF A SERIAL DATA FILE
:
REM This program opens a file and sets PTR to the end
REM before writing more data to it.
:
REM A function is used to open the file.
:
OSCLI "CD """+@usr$+""""
:
phonenos=FN_openend("PHONENOS.DAT")
PRINT "File Name PHONENOS.DAT Opened as Channel ";phonenos
PRINT
REPEAT
INPUT "Name ? " name$
IF name$="" THEN PROC_end
INPUT "Phone Number ? " phone$
PRINT
PRINT#phonenos,name$,phone$
UNTIL FALSE
:
DEF PROC_end
CLOSE#phonenos
END
:
:
REM Open the file 'AT END'.
:
REM If the file does not already exist, it is created
REM with OPENOUT. PTR# is left at zero and the file
REM number is returned. If the file exists, PTR# is
REM set to the end and the file number returned.
:
DEF FN_openend(name$)
LOCAL fnum
fnum=OPENUP(name$)
IF fnum=0 THEN fnum=OPENOUT(name$): =fnum
PTR#fnum=EXT#fnum
=fnum
REM F-WSER2
:
REM EXAMPLE OF WRITING TO A MIXED NUMERIC/CHAR DATA FILE
:
REM This program opens a data file and writes numeric
REM and character data to it. The use of OPENOUT
REM ensures that, even if the file existed before,
REM it is cleared before being written to.
:
REM Functions are used to accept and validate the
REM data before writing it to the file.
:
OSCLI "CD """+@usr$+""""
:
stats=OPENOUT("STATS.DAT")
PRINT "File Name STATS.DAT Opened as Channel ";stats
PRINT
REPEAT
name$=FN_name
IF name$="" THEN PROC_end
age=FN_age
height=FN_height
sex$=FN_sex
PRINT
PRINT#stats,name$,age,height,sex$
UNTIL FALSE
:
DEF PROC_end
PRINT "The file is ";EXT#stats;" bytes long"
CLOSE#stats
END
:
:
REM Accept a name from the keyboard and make sure it
REM consists only of spaces and upper or lower case
REM characters. Leading spaces are automatically
REM ignored on input.
:
DEF FN_name
LOCAL name$,FLAG,n
REPEAT
FLAG=TRUE
INPUT "Name ? " name$
IF name$<>"" THEN
FOR I=1 TO LEN(name$)
n=ASC(MID$(name$,I,1))
IF NOT(n=32 OR n>64 AND n<91 OR n>96 AND n<123) THEN FLAG=FALSE
NEXT
IF NOT FLAG THEN PRINT "No funny characters please !!!"
ENDIF
UNTIL FLAG
=name$
:
:
REM Accept the age from the keyboard and round to one
REM place of decimals. Ages of 0 and less or 150 or
REM more are considered to be in error.
:
DEF FN_age
LOCAL age
REPEAT
INPUT "What age ? " age
IF age<=0 OR age >=150 THEN PRINT "No impossible ages please !!!"
UNTIL age>0 AND age<150
=INT(age*10+.5)/10
:
:
REM Accept the height in centimeters from the keyboard
REM and round to an integer. Heights of 50 or less and
REM 230 or more are considered to be in error.
:
DEF FN_height
LOCAL height
REPEAT
INPUT "Height in centimeters ? " height
IF height<=50 OR height>=230 THEN PRINT "Verry funny !!!"
UNTIL height>50 AND height<230
=INT(height+.5)
:
:
REM Accept the sex from the keyboard. Only words
REM beginning with upper or lower case M or F are OK.
REM The returned string is truncated to 1 character.
:
DEF FN_sex
LOCAL sex$,FLAG
REPEAT
FLAG=TRUE
INPUT "Male or Female - M or F ? " sex$
IF sex$<>"" THEN sex$=CHR$(ASC(MID$(sex$,1,1)) AND 95)
IF sex$<>"M" AND sex$<>"F" THEN FLAG=FALSE
IF NOT FLAG THEN PRINT "No more sex(es) please !!!"
UNTIL FLAG
=sex$
REM F-RSER2
:
REM EXAMPLE OF READING FROM A MIXED NUMERIC/CHAR DATA FILE
:
REM This program opens a data file and reads numeric and
REM character data from it.
:
OSCLI "CD """+@usr$+""""
:
stats=OPENIN("STATS.DAT")
PRINT "File Name STATS.DAT Opened as Channel ";stats
PRINT
REPEAT
INPUT#stats,name$,age,height,sex$
PRINT "Name ";name$
PRINT "Age ";age
PRINT "Height in centimeters ";height
IF sex$="M" THEN PRINT "Male" ELSE PRINT "Female"
PRINT
UNTIL EOF#stats
:
CLOSE#stats
END
REM F-WESER2
:
REM EXAMPLE OF WRITING AT THE END OF A MIXED NUMERIC/CHAR
REM DATA FILE
:
REM This program opens a data file, sets PTR to its end
REM and then writes numeric and character data to it.
:
REM Functions are used to accept and validate the data
REM before writing it to the file.
:
OSCLI "CD """+@usr$+""""
:
stats=FN_open("STATS.DAT")
PRINT "File Name STATS.DAT Opened as Channel ";stats
PRINT
REPEAT
name$=FN_name
IF name$="" THEN PROC_end
age=FN_age
height=FN_height
sex$=FN_sex
PRINT
PRINT#stats,name$,age,height,sex$
UNTIL FALSE
:
DEF PROC_end
PRINT "The file is ";EXT#stats;" bytes long"
CLOSE#stats
END
:
:
REM Open the file. If it exists, set PTR# to the end and
REM return the file number. If it does not exist, open it,
REM leave PTR# as it is and return the file number.
:
DEF FN_open(name$)
LOCAL fnum
fnum=OPENUP(name$)
IF fnum=0 THEN fnum=OPENOUT(name$): =fnum
PTR#fnum=EXT#fnum
=fnum
:
:
REM Accept a name from the keyboard and make sure it
REM consists of spaces and upper or lower case characters.
REM Leading spaces are automatically ignored on input.
:
DEF FN_name
LOCAL name$,FLAG,n
REPEAT
FLAG=TRUE
INPUT "Name ? " name$
IF name$<>"" THEN
FOR I=1 TO LEN(name$)
n=ASC(MID$(name$,I,1))
IF NOT(n=32 OR n>64 AND n<91 OR n>96 AND n<123) THEN FLAG=FALSE
NEXT
IF NOT FLAG THEN PRINT "No funny characters please !!!"
ENDIF
UNTIL FLAG
=name$
:
:
REM Accept the age from the keyboard and round to one place
REM of decimals. decimals. Ages of 0 and less or 150 or
REM more are in error.
:
DEF FN_age
LOCAL age
REPEAT
INPUT "What age ? " age
IF age<=0 OR age >=150 THEN PRINT "No impossible ages please !!!"
UNTIL age>0 AND age<150
=INT(age*10+.5)/10
:
:
REM Accept the height in centimeters from the keyboard and
REM round to an integer. Heights of 50 or less and 230 or
REM more are in error.
:
DEF FN_height
LOCAL height
REPEAT
INPUT "Height in centimeters ? " height
IF height<=50 OR height>=230 THEN PRINT "Very funny !!!"
UNTIL height>50 AND height<230
=INT(height+.5)
:
:
REM Accept the sex from the keyboard. Only words beginning
REM with upper or lower case M or F are acceptable. The
REM returned string is truncated to 1 character.
:
DEF FN_sex
LOCAL sex$,FLAG
REPEAT
FLAG=TRUE
INPUT "Male or Female - M or F ? " sex$
IF sex$<>"" THEN sex$=CHR$(ASC(MID$(sex$,1,1)) AND 95)
IF sex$<>"M" AND sex$<>"F" THEN FLAG=FALSE
IF NOT FLAG THEN PRINT "No more sex(es) please !!!"
UNTIL FLAG
=sex$
REM F-WSTD
:
REM EXAMPLE OF WRITING A COMPATIBLE DATA FILE
:
REM This program opens a data file and writes numeric and
REM character data to it in a compatible format. Numerics
REM are changed to strings before they are written and the
REM data items are separated by commas. Each record is
REM terminated by CR LF and the file is terminated by a
REM Control Z.
:
REM Functions are used to accept and validate the data
REM before writing it to the file.
:
OSCLI "CD """+@usr$+""""
:
compat=OPENOUT("COMPAT.DAT")
PRINT "File Name COMPAT.DAT Opened as Channel ";compat
PRINT
REPEAT
name$=FN_name
IF name$="" THEN PROC_end
age=FN_age
height=FN_height
sex$=FN_sex
PRINT
record$=name$+","+STR$(age)+","+STR$(height)+","+sex$
PRINT#compat,record$
BPUT#compat,&0A
UNTIL FALSE
:
DEF PROC_end
BPUT#compat,&1A
CLOSE#compat
END
:
:
REM Accept a name from the keyboard and make sure it
REM consists only of spaces and upper or lower case
REM characters. Leading spaces are automatically ignored
REM on input.
:
DEF FN_name
LOCAL name$,FLAG,n
REPEAT
FLAG=TRUE
INPUT "Name ? " name$
IF name$<>"" THEN
FOR I=1 TO LEN(name$)
n=ASC(MID$(name$,I,1))
IF NOT(n=32 OR n>64 AND n<91 OR n>96 AND n<123) THEN FLAG=TRUE
NEXT
IF NOT FLAG THEN PRINT "No funny characters please !!!"
ENDIF
UNTIL FLAG
=name$
:
:
REM Accept the age from the keyboard and round to one place
REM of decimals. Ages of 0 and less or 150 or more are
REM considered to be in error.
:
DEF FN_age
LOCAL age
REPEAT
INPUT "What age ? " age
IF age<=0 OR age >=150 THEN PRINT "No impossible ages please !!!"
UNTIL age>0 AND age<150
=INT(age*10+.5)/10
:
:
REM Accept the height in centimeters from the keyboard and
REM round to an integer. Heights of 50 or less and 230 or
REM more are considered to be in error.
:
DEF FN_height
LOCAL height
REPEAT
INPUT "Height in centimeters ? " height
IF height<=50 OR height>=230 THEN PRINT "Verry funny !!!"
UNTIL height>50 AND height<230
=INT(height+.5)
:
:
REM Accept the sex from the keyboard. Only words beginning
REM with upper or lower case M or F are acceptable. The
REM returned string is truncated to 1 character.
:
DEF FN_sex
LOCAL sex$,FLAG
REPEAT
FLAG=TRUE
INPUT "Male or Female - M or F ? " sex$
IF sex$<>"" THEN sex$=CHR$(ASC(MID$(sex$,1,1)) AND 95)
IF sex$<>"M" AND sex$<>"F" THEN FLAG=FALSE
IF NOT FLAG THEN PRINT "No more sex(es) please !!!"
UNTIL FLAG
=sex$
REM F-RSTD
:
REM EXAMPLE OF READING A COMPATIBLE DATA FILE
:
REM This program opens a data file and reads numeric and
REM character data from it. The data is read a byte at a
REM time and the appropriate action taken depending on
REM whether it is a character, a comma, or a control char.
:
OSCLI "CD """+@usr$+""""
:
compat=OPENUP("COMPAT.DAT")
PRINT "File Name COMPAT.DAT Opened as Channel ";compat
PRINT
REPEAT
name$=FN_read
PRINT "Name ";name$
age=VAL(FN_read)
PRINT "Age ";age
height=VAL(FN_read)
PRINT "Height in centimeters ";height
sex$=FN_read
IF sex$="M" THEN PRINT "Male" ELSE PRINT "Female"
PRINT
UNTIL FALSE
:
:
REM Read a data item from the file. Treat commas and CRs
REM as data item terminators and Control Z as the file
REM terminator. Since we are not interested in reading a
REM record at a time, the record terminator CR LF is of no
REM special interest to us. We use the CR, along with
REM commas, as a data item separator and discard the LF.
:
DEF FN_read
LOCAL data$,byte$,byte
dat$=""
REPEAT
byte=BGET#compat
IF byte=&1A OR EOF#compat THEN CLOSE#compat: END
IF NOT(byte=&0A OR byte=&0D OR byte=&2C) THEN data$=data$+CHR$(byte)
UNTIL byte=&0D OR byte=&2C
=data$
We haven't finished yet, however. We need to be able to tell whether any one record is 'live' or empty (or deleted). To do this we need an extra byte at the start of each record which we set to one value for 'empty' and another for 'live'. In all the examples we use 0 to indicate 'empty' and NOT 0 to indicate 'live'. We are writing character data to the file so we could use the first byte of the name string as the indicator because the lowest ASCII code we will be storing is 32 (space). You can't do this for mixed data files because this byte could hold a data value of zero. Because of this, we have chosen to use an additional byte for the indicator in all the examples.
Our logical record thus consists of:
Thus the maximum amount of data in each record is 83 bytes. Because we cannot tell in advance how big each record needs to be (and we may want to change it later), we must assume that ALL the records will be this length. Since most of the records will be smaller than this, we are going to waste quite a lot of space in our random access file, but this is the penalty we pay for convenience and comparative simplicity.
1 indicator byte 31 bytes for the name 51 bytes for the remarks
When we write the data to the file, we could insist that each field was treated as a fixed length field by packing each string out with spaces to make it the 'correct' length. This would force each field to start at its 'proper' byte within the record. We don't need to do this, however, because we aren't going to randomly access the fields within the record; we know the order of the fields within the record and we are going to read them sequentially into appropriately named variables. We can write the fields to the file with each field following on immediately behind the previous one. All the 'spare' room is now left at the end of the record and not split up at the end of each field.
To start with, let's call the first record on the file 'record zero', the second record 'record 1', the third record 'record 2', etc. The first byte of 'record zero' is at byte zero on the file. The first byte of 'record 1' is at byte 83 on the file. The first byte of 'record 2' is at byte 166 (2*83) on the file. And so on. So, the start point of any record can be calculated by:
Now, we need to set PTR# to the position of this byte in order to access the record. If the record number was held in 'recno' and the channel number in 'fnum', we could do this directly by:first_byte= 83*record_number
However, we may want to do this in several places in the program so it would be better to define and use a function to set PTR# as illustrated below.PTR#fnum=83*recno
Whilst the computer is quite happy with the first record being 'record zero', us mere humans find it a little confusing. What we need is to be able to call the first record 'record 1', etc. We could do this without altering the function which calculates the start position of each record, but we would waste the space allocated to 'record 0' since we would never use it. We want to call it 'record 1' and the program wants to call it 'record 0'. We can change the function to cater for this. If we subtract 1 from the record number before we multiply it by the record length, we will get the result we want. Record 1 will start at byte zero, record 2 will start at byte 83, etc. Our function now looks like this:PTR#fnum=FN_ptr(recno) DEF FN_ptr(record)=83*record
In our example so far we have used a record length of 83. If we replace this with a variable 'rec_len' we have a general function which we can use to calculate the start position of any record in the file in any program (you will need to set rec_len to the appropriate value at the start of the program). The function now becomes:DEF FN_ptr(record)=83*(record-1)
We use this function (or something very similar to it) in the following three example programs using random access files.DEF FN_ptr(record)=rec_len*(record-1)
REM F-RAND1
:
REM VERY SIMPLE RANDOM ACCESS PROGRAM
:
REM This program maintains a random access file of names
REM and remarks. There is room for a maximum of 20
REM entries. Each name can be up to a maximum of 30
REM characters long and each remark up to 50 characters.
REM The first byte of the record is set non zero (in fact
REM &FF) if there is a record present. This gives a
REM maximum record length of 1+31+51=83. (Don't forget
REM the CRs.)
:
OSCLI "CD """+@usr$+""""
:
bell$=CHR$(7)
temp$=STRING$(50," ")
maxrec=20
rec_len=83
ans$=""
CLS
WIDTH 0
fnum=OPENUP "RANDONE.DAT"
IF fnum=0 fnum=FN_setup("RANDONE.DAT")
REPEAT
REPEAT
INPUT '"Enter record number: "ans$
IF ans$="0" CLOSE#fnum:CLS:END
IF ans$="" record=record+1 ELSE record=VAL(ans$)
IF record<1 OR record>maxrec PRINT bell$;
UNTIL record>0 AND record<=maxrec
PTR#fnum=FN_ptr(record)
PROC_display
INPUT '"Do you wish to change this record",ans$
PTR#fnum=FN_ptr(record)
IF FN_test(ans$) PROC_modify
UNTIL FALSE
END
:
:
DEF FN_test(A$) =LEFT$(A$,1)="Y" OR LEFT$(A$,1)="y"
:
:
DEF FN_ptr(record)=rec_len*(record-1)
REM This makes record 1 start at PTR# = 0
:
:
DEF PROC_display
PRINT '"Record number ";record'
flag=BGET#fnum
IF flag=0 PROC_clear:ENDPROC
INPUT#fnum,name$,remark$
PRINT name$;" ";remark$ '
ENDPROC
:
:
DEF PROC_clear
PRINT "Record empty"
name$=""
remark$=""
ENDPROC
:
:
DEF PROC_modify
PRINT '"(Enter <RETURN> for no change or DELETE to delete)"'
INPUT "Name ",temp$
temp$=LEFT$(temp$,30)
IF temp$<>"" name$=temp$
INPUT "Remark ",temp$
temp$=LEFT$(temp$,50)
IF temp$<>"" remark$=temp$
INPUT '"Confirm update record",ans$
IF NOT FN_test(ans$) ENDPROC
IF name$="DELETE" BPUT#fnum,0:ENDPROC
BPUT#fnum,255
PRINT#fnum,name$,remark$
ENDPROC
:
:
DEF FN_setup(fname$)
PRINT "Setting up the database file"
fnum=OPENOUT(fname$)
FOR record=1 TO maxrec
BPUT#fnum,0
PTR#fnum=FN_ptr(record)
NEXT
=fnum
REM F-RAND2
REM SIMPLE DATABASE PROGRAM
REM Written by R T Russell Jan 1983
REM Modified for BBCBASIC(86) by Doug Mounter Dec 1985
:
REM This is a simple database program. You are asked for
REM the name of the file you wish to use. If the file
REM does not already exist, you are asked to specify the
REM number and format of the records. If the file does
REM already exist, the file specification is read from
REM the file.
:
OSCLI "CD """+@usr$+""""
:
@%=10
bell$=CHR$(7)
CLS
WIDTH 0
INPUT '"Enter the filename of the data file: "filename$
fnum=OPENUP(filename$)
IF fnum=0 fnum=FN_setup(filename$) ELSE PROC_readgen
PRINT
:
REPEAT
REPEAT
INPUT '"Enter record number: "ans$
IF ans$="0" CLOSE#fnum:CLS:END
IF ans$="" record=record+1 ELSE record=VAL(ans$)
IF record<1 OR record>maxrec PRINT bell$;
UNTIL record>0 AND record<=maxrec
PTR#fnum=FN_ptr(record)
PROC_display
INPUT '"Do you wish to change this record",ans$
PTR#fnum=FN_ptr(record)
IF FN_test(ans$) PROC_modify
UNTIL FALSE
END
:
:
DEF FN_test(A$) =LEFT$(A$,1)="Y" OR LEFT$(A$,1)="y"
:
:
DEF FN_ptr(record)=base+rec_len*(record-1)
:
:
DEF FN_setup(filename$)
PRINT "New file."
fnum=OPENOUT(filename$)
REPEAT
INPUT "Enter the number of records (max 1000): "maxrec
UNTIL maxrec>0 AND maxrec<1001
REPEAT
INPUT "Enter number of fields per record (max 20): "fields
UNTIL fields>0 AND fields<21
DIM title$(fields),size(fields),A$(fields)
FOR field=1 TO fields
PRINT '"Enter title of field number ";field;": ";
INPUT ""title$(field)
PRINT
REPEAT
INPUT "Maximum size of field (characters)",size(field)
UNTIL size(field)>0 AND size(field)<256
NEXT field
rec_len=1
PRINT#fnum,maxrec,fields
FOR field=1 TO fields
PRINT#fnum,title$(field),size(field)
rec_len=rec_len+size(field)+1
NEXT field
base=PTR#fnum
:
FOR record=1 TO maxrec
PTR#fnum=FN_ptr(record)
BPUT#fnum,0
NEXT
=fnum
:
:
DEF PROC_readgen
rec_len=1
INPUT#fnum,maxrec,fields
DIM title$(fields),size(fields),A$(fields)
FOR field=1 TO fields
INPUT#fnum,title$(field),size(field)
rec_len=rec_len+size(field)+1
NEXT field
base=PTR#fnum
ENDPROC
:
:
DEF PROC_display
PRINT '"Record number ";record'
flag=BGET#fnum
IF flag=0 PROC_clear:ENDPROC
FOR field=1 TO fields
INPUT#fnum,A$(field)
PRINT title$(field);" ";A$(field)
NEXT field
ENDPROC
:
:
DEF PROC_clear
FOR field=1 TO fields
A$(field)=""
NEXT
ENDPROC
:
:
DEF PROC_modify
PRINT '"(Enter <RETURN> for no change)"'
FOR field=1 TO fields
REPEAT
PRINT title$(field);" ";
INPUT LINE ""A$
IF A$="" PRINT TAB(POS,VPOS-1)title$(field);" ";A$(field)
REM TAB(POS,VPOS-1) moves the cursor up 1 line
UNTIL LEN(A$)<=size(field)
IF A$<>"" A$(field)=A$
NEXT field
INPUT '"Confirm update record",ans$
IF NOT FN_test(ans$) ENDPROC
IF A$(1)="DELETE" BPUT#fnum,0:ENDPROC
BPUT#fnum,255
FOR field=1 TO fields
PRINT#fnum,A$(field)
NEXT field
ENDPROC
REM F-RAND3
:
REM Written by Doug Mounter - Jan 1982
REM Modified for BBCBASIC(86) Dec 1985
:
REM EXAMPLE OF A RANDOM ACCESS FILE
:
REM This is a simple inventory program. It uses the
REM item's part number as the key and stores:
REM The item description - character max length 30
REM The quantity in stock - numeric
REM The re-order level - numeric
REM The unit price - numeric
REM In addition, the first byte of the record is used
REM as a valid data flag. Set to 0 if empty, D if the
REM record has been deleted or V if the record is
REM valid.
REM This gives a MAX record length of 47 bytes
REM (Don't forget the CR after the string)
:
PROC_initialise
inventry=FN_open("INVENTRY.DAT")
The following section of code
is the command loop. You are offered a choice of functions until
you eventually select function 0. The
CASE statement
is used for menu selection processing:
REPEAT
CLS
PRINT TAB(5,3);"If you want to:-"'
PRINT TAB(10);"End This Session";TAB(55);"Type 0"
PRINT TAB(10);"Amend or Create an Entry";TAB(55);"Type 1"
PRINT TAB(10);"Display the Inventory for One Part";TAB(55);"Type 2"
PRINT TAB(10);"Change the Stock Level of One Part";TAB(55);"Type 3"
PRINT TAB(10);"Display All Items Below Reorder Level";TAB(55);"Type 4"
PRINT TAB(10);"Recover a Previously Deleted Item";TAB(55);"Type 5"
PRINT TAB(10);"List Deleted Items";TAB(55);"Type 6"
PRINT TAB(10);"Set Up a New Inventory";TAB(55);"Type 9"
REPEAT
PRINT TAB(5,15);bell$;
PRINT "Please enter the appropriate number (0 to 6 or 9) ";
function$=GET$
UNTIL function$>"/" AND function$<"8" OR function$="9"
function=VAL(function$)
CASE function OF
WHEN 1: PROCcreateentry
WHEN 2: PROCdisplaypart
WHEN 3: PROCchangepart
WHEN 4: PROCreorder
WHEN 5: PROCrecover
WHEN 6: PROClistdeleted
WHEN 9: PROCnew
ENDCASE
UNTIL function=0
CLS
PRINT "Inventory File Closed" ''
CLOSE#inventry
END
This is the data entry function. You can delete or amend
an entry or enter a new one. Have a look at the definition of FN_getrec
for an explanation of the
ASC"V" in its parameters:
This subroutine allows you to look at a record without the ability to change or delete it:REM AMEND/CREATE AN ENTRY DEF PROCcreateentry REPEAT CLS PRINT "AMEND/CREATE" partno=FN_getpartno flag=FN_getrec(partno,ASC"V") PROC_display(flag) PRINT'"Do you wish to "; IF flag PRINT "change this entry ? "; ELSE PRINT "enter data ? "; IF (GET AND &5F)<>ASC"N" flag=FN_amend(partno):PROC_cteos PROC_write(partno,flag,type) PRINT bell$;"Do you wish to amend/create another record ? "; UNTIL (GET AND &5F)=ASC"N" ENDPROC
The purpose of this subroutine is to allow you to update the stock level without having to amend the rest of the record:REM DISPLAY AN ENTRY DEF PROCdisplaypart REPEAT CLS PRINT "DISPLAY" partno=FN_getpartno flag=FN_getrec(partno,ASC"V") PROC_display(flag) PRINT ' PRINT "Do you wish to view another record ? "; UNTIL (GET AND &5F)=ASC"N" ENDPROC
REM CHANGE THE STOCK LEVEL FOR ONE PART
DEF PROCchangepart
REPEAT
CLS
PRINT "CHANGE STOCK"
partno=FN_getpartno
flag=FN_getrec(partno,ASC"V")
REPEAT
PROC_display(flag)
PROC_cteos
REPEAT
PRINT TAB(0,12);:PROC_cteol
INPUT "What is the stock change ? " temp$
change=VAL(temp$)
UNTIL INT(change)=change AND stock+change>=0
IF temp$="" THEN
flag=FALSE
ELSE
stock=stock+change
PROC_display(flag)
PRINT'"Is this correct ? ";
temp$=GET$
ENDIF
UNTIL NOT flag OR temp$="Y" OR temp$="y"
PROC_write(partno,flag,ASC"V")
PRINT return$;bell$;
PRINT "Do you want to update any more stock levels ? ";
UNTIL (GET AND &5F)=ASC"N"
ENDPROC
This subroutine goes through the file in stock number
order and lists all those items where the current stock is below the
reorder level. You can interrupt the process at any time by pushing
a key:
REM DISPLAY ITEMS BELOW REORDER LEVEL
DEF PROCreorder
partno=1
REPEAT
CLS
PRINT "ITEMS BELOW REORDER LEVEL"'
line_count=2
REPEAT
flag=FN_getrec(partno,ASC"V")
IF (flag AND stock<reord) THEN
PRINT "Part Number ";partno
PRINT desc$;" Stock ";stock;" Reorder Level ";reord
PRINT
line_count=line_count+3
ENDIF
partno=partno+1
temp$=INKEY$(0)
UNTIL partno>maxpartno OR line_count>20 OR temp$<>""
PRINT TAB(0,23);bell$;"Press any key to continue or E to end ";
temp$=GET$
UNTIL partno>maxpartno OR temp$="E" OR temp$="e"
partno=0
ENDPROC
Deleted entries are not actually removed from the file,
just marked as deleted. This subroutine makes it possible for you
to correct the mistake you made by deleting data you really wanted. If
you have never used this type of program seriously, you won't believe
how useful this is:
REM RECOVER A DELETED ENTRY
DEF PROCrecover
REPEAT
CLS
PRINT "RECOVER DELETED RECORDS"
partno=FN_getpartno
flag=FN_getrec(partno,ASC"D")
PROC_display(flag)
PRINT
IF flag THEN
PRINT "If you wish to recover this entry type Y ";
temp$=GET$
IF temp$="Y" OR temp$="y" PROC_write(partno,flag,ASC"V")
ENDIF
PRINT return$;bell$;"Do you wish to recover another record ? ";
UNTIL (GET AND &5F)=ASC"N"
ENDPROC
This subroutine lists all the deleted entries so you
can check you really don't want the data:
REM LIST DELETED ENTRIES
DEF PROClistdeleted
partno=1
REPEAT
CLS
PRINT "DELETED ITEMS"'
line_count=2
REPEAT
flag=FN_getrec(partno,ASC"D")
IF flag THEN
PRINT "Part Number ";partno
PRINT "Description ";desc$'
line_count=line_count+3
ENDIF
partno=partno+1
temp$=INKEY$(0)
UNTIL partno>maxpartno OR line_count>20 OR temp$<>""
PRINT TAB(0,23);bell$;"Press any key to continue or E to end ";
UNTIL partno>maxpartno OR (GET AND &5F)=ASC"E"
partno=0
ENDPROC
:
:
REM REINITIALISE THE INVENTORY DATA FILE
DEF PROCnew
CLS
PRINT TAB(0,3);bell$;"Are you sure you want to set up a new inventory?"
PRINT "You will DESTROY ALL THE DATA YOU HAVE ACCUMULATED so far."
PRINT "If you are SURE you want to do it, enter YES"
INPUT "Otherwise, just hit Return ",temp$
IF temp$="YES" PROC_setup(inventry)
ENDPROC
This is where all the variables that you usually write as
CHR$(#) go.
Then you can find them if you want to change them:
It's a new file, so we won't go through the warning bit.REM INITIALISE ALL THE VARIOUS PRESETS ETC : DEF PROC_initialise CLS bell$=CHR$(7) return$=CHR$(13) rec_length=47 partno=0 desc$=STRING$(30," ") temp$=STRING$(40," ") WIDTH 0 OSCLI "CD """+@usr$+"""" ENDPROC : REM OPEN THE FILE AND RETURN THE FILE NUMBER : REM If the file already exists, the largest permitted REM part number is read into maxpartno. REM If it is a new file, file initialisation is carried REM out and the largest permitted part number is REM written as the first record. : DEF FN_open(name$) fnum=OPENUP(name$) IF fnum>0 INPUT#fnum,maxpartno: =fnum fnum=OPENOUT(name$) CLS PROC_setup(fnum) =fnum
Ask for the required part number. If a null is entered, make the next part number one more than the last:REM SET UP THE FILE : REM Ask for the maximum part number required, write REM it as the first record and then write 0 in to REM the first byte of every record. : DEF PROC_setup(fnum) REPEAT PRINT TAB(0,12);bell$;:PROC_cteos INPUT "What is the highest part number required (Max 4999) ",maxpartno UNTIL maxpartno>0 AND maxpartno<5000 AND INT(maxpartno)=maxpartno PTR#fnum=0 PRINT#fnum,maxpartno FOR partno=1 TO maxpartno PTR#fnum=FN_ptr(partno) BPUT#fnum,0 NEXT partno=0 ENDPROC
REM GET AND RETURN THE REQUIRED PART NUMBER
:
DEF FN_getpartno
REPEAT
PRINT TAB(0,5);bell$;:PROC_cteos
PRINT "Enter a Part Number Between 1 and ";maxpartno '
IF partno<>maxpartno THEN
PRINT "The Next Part Number is ";partno+1;
PRINT " Just hit Return to get this"'
ENDIF
INPUT "What is the Part Number You Want ",partno$
IF partno$<>"" THEN
partno=VAL(partno$)
ELSE
IF partno=maxpartno partno=0 ELSE partno=partno+1
ENDIF
PRINT TAB(35,9);partno;:PROC_cteol
UNTIL partno>0 AND partno<maxpartno+1 AND INT(partno)=partno
=partno
:
:
REM GET THE RECORD FOR THE PART NUMBER
:
REM Return TRUE if the record exists and FALSE if not
REM If the record does not exist, load desc$ with "No Record"
REM The remainder of the record is set to 0
:
DEF FN_getrec(partno,type)
stock=0
reord=0
price=0
PTR#inventry=FN_ptr(partno)
test=BGET#inventry
IF test=0 desc$="No Record": =FALSE
IF test<>type THEN
IF type=86 desc$="Record Deleted" ELSE desc$="Record Exists"
=FALSE
ENDIF
INPUT#inventry,desc$
INPUT#inventry,stock,reord,price
=TRUE
Part numbers run from 1 up. The record for
part number 1 starts at byte 5 of the file. The start position could
have been calculated as (part-no -1) *record_length + 5. The
expression below works out to the same thing, but it executes quicker:
This function amends the record as required and returns with flag=TRUE if any amendment has taken place. It also sets the record type indicator (valid deleted or no record) to ASC"V" or ASC"D" as appropriate:REM CALCULATE THE VALUE OF PTR FOR THIS RECORD : DEF FN_ptr(partno)=partno*rec_length+5-rec_length
Write the record to the file if necessary (flag=TRUE):REM AMEND THE RECORD : DEF FN_amend(partno) PRINT return$;:PROC_cteol:PRINT TAB(0,4); PRINT "Please Complete the Details for Part Number ";partno PRINT "Just hit Return to leave the entry as it is"' flag=FALSE type=ASC"V" INPUT "Description - Max 30 Chars " temp$ IF temp$="DELETE" type=ASC"D": =TRUE temp$=LEFT$(temp$,30) IF temp$<>"" desc$=temp$:flag=TRUE IF desc$="No Record" OR desc$="Record Deleted" =FALSE INPUT "Current Stock Level " temp$ IF temp$<>"" stock=VAL(temp$):flag=TRUE INPUT "Reorder Level " temp$ IF temp$<>"" reord=VAL(temp$):flag=TRUE INPUT "Unit Price " temp$ IF temp$<>"" price=VAL(temp$):flag=TRUE =flag
Print the record details to the screen. If the record is not of the required type (V or D) or it does not exist, stop after printing the description. The description holds "Record Exists" or "Record Deleted" or valid data as set by FN_getrec:REM WRITE THE RECORD : DEF PROC_write(partno,flag,type) IF NOT flag ENDPROC PTR#inventry=FN_ptr(partno) BPUT#inventry,type PRINT#inventry,desc$,stock,reord,price ENDPROC
The following two procedures rely on there being 80 characters per line and 25 lines (for example when MODE 3 or 16 is selected):REM DISPLAY THE RECORD DETAILS : DEF PROC_display(flag) PRINT TAB(0,5);:PROC_cteos PRINT "Part Number ";partno' PRINT "Description ";desc$ IF NOT flag ENDPROC PRINT "Current Stock Level ";stock PRINT "Reorder Level ";reord PRINT "Unit Price ";price ENDPROC
REM There are no 'native' clear to end of line/screen REM vdu procedures. The following 2 procedures clear to REM the end of the line/screen. : DEF PROC_cteol LOCAL x,y x=POS:y=VPOS REPEAT VDU 32 : UNTIL POS=0 PRINT TAB(x,y); ENDPROC : : DEF PROC_cteos LOCAL x,y x=POS:y=VPOS WHILE VPOS<24 VDU 32 : ENDWHILE REPEAT VDU 32 : UNTIL POS=0 PRINT TAB(x,y); ENDPROC
NAME.NDX (index file)
| maxrec 5 bytes |
length 5 bytes |
index$(1) 1 to 31 bytes |
index(1) 5 bytes |
index$(2) 1 to 31 bytes |
index(2) 5 bytes |
etc. |
Where index(n) points to a record in the data file as follows:
ADDRESS.DTA (data file)
| Phone Num 1 to 31 bytes |
Address 1 1 to 31 bytes |
Address 2 1 to 31 bytes |
Address 3 1 to 31 bytes |
Address 4 1 to 31 bytes |
Post Code 1 to 31 bytes |
| maxrec | Is the maximum number of records permitted in this file. The practical limit is governed by the amount of memory available for the index arrays which are held in memory. |
| length | Is the number of entries in the index. |
| index(n) | Is the value of PTR#datanum just prior to the first byte of the data for this entry being written to it. In the Random File examples this value was calculated and it increased by a constant amount for every record. |
REM F-INDEX
REM EXAMPLE OF AN INDEXED FILE
:
REM Written by Doug Mounter - Feb 1982
REM Modified for BBCBASIC(86) - Dec 1985
:
REM This is a simple address book filing system. It will
REM accept names, telephone numbers and addresses and store
REM them in a file called ADDRESS.DTA. The index is in
REM name order and is kept in a file called NAME.NDX.
REM All the fields are character and the maximum length
REM of any field is 30.
:
PROC_initialise
PROC_open_files
ON ERROR IF ERR<>17 PRINT:REPORT:PRINT" At line ";ERL:END
REPEAT
CLS
PRINT TAB(5,3);"If you want to:-" '
PRINT TAB(10);"End This Session";TAB(55);"Type 0"
PRINT TAB(10);"Enter Data";TAB(55);"Type 1"
PRINT TAB(10);"Search For/Delete an Entry";TAB(55);"Type 2"
PRINT TAB(10);"List in Alphabetical Order";TAB(55);"Type 3"
PRINT TAB(10);"Reorganize the Data File and Index";TAB(55);"Type 4";
REPEAT
PRINT TAB(5,11);
PRINT "Please enter the appropriate number (0 to 4) ";
function$=GET$
PRINT return$;:PROC_cteol
UNTIL function$>"/" AND function$<"5"
function=VAL(function$)
PRINT TAB(54,function+5);"<====<";
ON function PROC_enter,PROC_search,PROC_list,PROC_reorg ELSE
UNTIL function=0
CLS
PROC_close_files
*ESC ON
PRINT "Address Book Files Closed"''
END
:
:
REM ENTER DATA
:
DEF PROC_enter
flag=TRUE
temp$=""
i=1
REPEAT
REPEAT
PROC_get_data
CASE TRUE OF
WHEN length=maxrec OR data$(1)="": flag=FALSE
WHEN data$(1)="+" OR data$(1)="-": PROC_message("Bad Data")
OTHERWISE:
i=FN_find_place(0,data$(1))
IF i>0 PROC_message("Duplicate Record")
PRINT '"Is this data correct ? ";
temp$=FN_yesno
IF temp$="N" PROC_message("Data NOT Accepted")
ENDCASE
UNTIL NOT flag OR temp$<>"N"
PROC_cteos
IF flag THEN
PROC_put_index(i,data$(1),PTR#datanum)
FOR i=2 TO 7
PRINT#datanum,data$(i)
NEXT
ENDIF
UNTIL NOT flag
ENDPROC
:
:
REM SEARCH FOR AN ENTRY
:
DEF PROC_search
i=0
REPEAT
PRINT TAB(0,11);:PROC_cteol
INPUT "What name do you want to look for ",name$
IF name$<>"" THEN
IF name$="DELETE" PROC_delete(i) ELSE i=FN_display(i,name$)
ENDIF
UNTIL name$=""
ENDPROC
:
:
REM LIST IN ALPHABETICAL ORDER
:
DEF PROC_list
entry=1
REPEAT
CLS
line_count=0
REPEAT
PRINT TAB(0,line_count);
PROC_read_data(entry)
PROC_print_data
entry=entry+1
line_count=line_count+8
temp$=INKEY$(0)
UNTIL entry>length OR line_count>16 OR temp$<>""
PROC_message("Push any key to continue or E to end ")
UNTIL entry>length OR (GET AND &5F)=ASC"E"
ENDPROC
:
:
REM REORGANIZE THE DATA FILE AND INDEX
:
DEF PROC_reorg
entry=1
PRINT TAB(0,13);"Reorganizing the Data File" '
newdata=OPENOUT"ADDRESS.BAK"
REPEAT
PROC_read_data(entry)
index(entry)=PTR#newdata
FOR i=2 TO 7
PRINT#newdata,data$(i)
NEXT
entry=entry+1
UNTIL entry>length
CLOSE#newdata : CLOSE#datanum
PRINT "Re-naming the Data File" '
*REN ADDRESS.BAK ADDRESS.$$$
PRINT "*";
*REN ADDRESS.DTA ADDRESS.BAK
PRINT "*";
*REN ADDRESS.$$$ ADDRESS.DTA
PRINT "*";
datanum=OPENUP "ADDRESS.DTA"
ENDPROC
:
:
REM INITIALISE VARIABLES AND ARRAYS
:
DEF PROC_initialise
CLS
*ESC OFF
esc$=CHR$(27)
bell$=CHR$(7)
return$=CHR$(13)
maxrec=100
OSCLI "CD """+@usr$+""""
:
REM The maximum record number, maxrec, is read in
REM PROC_read_index if the file already exists.
:
DIM message$(7)
FOR i=1 TO 7
READ message$(i)
NEXT
DATA Name,Phone Number,Address,-- " --,-- " --,-- " --,Post Code
:
DIM data$(7)
FOR i=1 TO 7
data$(i)=STRING$(30," ")
NEXT
temp$=STRING$(255," ")
temp$=""
:
ENDPROC
:
:
REM OPEN THE FILES
:
DEF PROC_open_files
indexnum=OPENUP"NAME.NDX"
datanum=OPENUP"ADDRESS.DTA"
IF indexnum=0 OR datanum=0 PROC_setup ELSE PROC_read_index
PTR#datanum=EXT#datanum
ENDPROC
:
:
REM SET UP NEW INDEX AND DATA FILES
:
DEF PROC_setup
CLS
PRINT TAB(0,13);"Setting Up Address Book"
indexnum=OPENOUT"NAME.NDX"
datanum=OPENOUT"ADDRESS.DTA"
length=0
PRINT#indexnum,maxrec,length
CLOSE#indexnum
DIM index$(maxrec+1),index(maxrec+1)
index$(0)=""
index(0)=0
index$(1)=CHR$(&FF)
index(1)=0
ENDPROC
:
:
REM READ INDEX AND LENGTH OF DATA FILE
:
DEF PROC_read_index
CLS
INPUT#indexnum,maxrec,length
DIM index$(maxrec+1), index(maxrec+1)
index$(0)=""
index(0)=0
FOR i=1 TO length
INPUT#indexnum,index$(i),index(i)
NEXT
CLOSE#indexnum
index$(length+1)=CHR$(&FF)
index(length+1)=0
ENDPROC
:
:
REM WRITE INDEX AND CLOSE FILES
:
DEF PROC_close_files
indexnum=OPENOUT"NAME.NDX"
PRINT#indexnum,maxrec,length
FOR i=1 TO length
PRINT#indexnum,index$(i),index(i)
NEXT
CLOSE#0
ENDPROC
:
:
REM WRITE A MESSAGE AT LINE 23
:
DEF PROC_message(line$)
LOCAL x,y
x=POS
y=VPOS
PRINT TAB(0,23);:PROC_cteol:PRINT bell$;line$;
PRINT TAB(x,y);
ENDPROC
:
:
REM GET A Y/N ANSWER
:
DEF FN_yesno
LOCAL temp$
temp$=GET$
IF temp$="y" OR temp$="Y" ="Y"
IF temp$="n" OR temp$="N" ="N"
=""
:
:
REM CLEAR 9 LINES FROM PRESENT POSITION
:
DEF PROC_clear9
LOCAL x,y,n
x=POS:y=VPOS:PRINT return$;
FOR n=1 TO 9 : REPEAT VDU 32 : UNTIL POS=0 : NEXT n
PRINT TAB(x,y);
ENDPROC
:
:
REM GET INPUT DATA - LIMIT TO 30 CHAR
:
DEF PROC_get_data
LOCAL i
PRINT TAB(0,13);
PROC_clear9
IF length=maxrec PROC_message("Address Book Full")
FOR i=1 TO 7
PRINT TAB(10);message$(i);TAB(25);
INPUT temp$
data$(i)=LEFT$(temp$,30)
IF data$(1)="" i=7
NEXT
ENDPROC
:
:
REM FIND AND DISPLAY THE REQUESTED DATA
:
DEF FN_display(i,name$)
PRINT TAB(0,12);:PROC_cteos
i=FN_find_place(i,name$)
IF i<0 PROC_message("Name Not Known - Next Highest Given")
PROC_read_data(i)
PRINT
PROC_print_data
=i
Move everything below the entry you want deleted up one
and subtract 1 from the length:
Get the start of the position of the start of the data record for entry 'i' in the index and read it into the buffer array data$(). Save the current value of the data file pointer on entry and restore it before leaving:REM DELETE THE ENTRY FROM THE INDEX : DEF PROC_delete(i) INPUT "Are you SURE ",temp$ PRINT TAB(0,VPOS-1);:PROC_cteos IF temp$<>"YES" ENDPROC IF i<0 i=-i FOR i=i TO length index$(i)=index$(i+1) index(i)=index(i+1) NEXT length=length-1 ENDPROC
Move all the directory entries from position i onwards down the index (in fact you have to start at the end and work back). Slot the new entry in the gap made at position i and add 1 to the length:REM READ DATA FOR ENTRY i : DEF PROC_read_data(i) PTRdata=PTR#datanum IF i<0 i=-i PTR#datanum=index(i) data$(1)=index$(i) FOR i=2 TO 7 INPUT#datanum,data$(i) NEXT PTR#datanum=PTRdata ENDPROC : : REM PRINT data$() ON VDU : DEF PROC_print_data LOCAL i FOR i=1 TO 7 IF data$(i)<>"" PRINT TAB(10);message$(i);TAB(25);data$(i) IF data$(1)=CHR$(&FF) i=7 NEXT ENDPROC
This function looks in the index for the string entry$. If it finds it it returns with i set to its position in the index. If not, i is set to minus the position of the next highest string (in other words, the position you wish to put the a new entry). Thus if a part of the index looked like:REM PUT A NEW ENTRY IN INDEX AT POSITION i : DEF PROC_put_index(i,entry$,ptr) LOCAL j IF i<0 i=-i FOR j=length+1 TO i STEP -1 index$(j+1)=index$(j) index(j+1)=index(j) NEXT index$(i)=entry$ index(i)=ptr length=length+1 ENDPROC
and you entered with FRED, it would return 35. However if you entered with GEORGE, it would return -36.
(34) BERT (35) FRED (36) JOHN
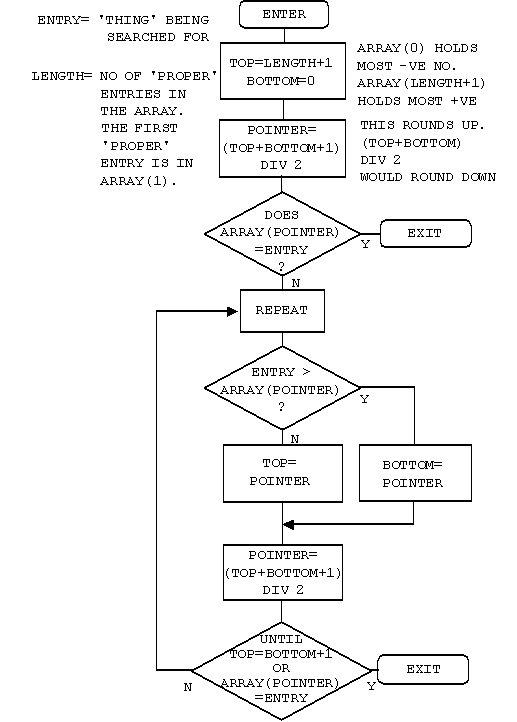
The function consists of two parts. The first looks at the entry$ to see if it should just up or down the entry number by 1, taking account of wrap-around at the start and end of the index. The second part is the binary chop advertised with such telling wit in the introduction to indexed files. Since we enter this function with the entry pointer i set to its previous value, we must cater for a negative value.
Here, at last, T H E B I N A R Y C H O PREM FIND ENTRY IN INDEX OR PLACE TO PUT IT : DEF FN_find_place(i,entry$) LOCAL top,bottom IF i<0 i=-i IF entry$="+" AND i<length =i+1 IF entry$="+" AND i=length =1 IF entry$="-" AND i>1 =i-1 IF entry$="-" AND i<2 =length
This bit moves the pointer up the index to the first of any duplicate entries.top=length+1 bottom=0 i=(top+1) DIV 2 IF entry$<>index$(i) i=FN_search(entry$) REPEAT IF entry$=index$(i-1) i=i-1
The two following procedures rely on mode 3 or 7 being selected. They will not work properly if a graphics mode has been selected or if some characters on the screen have attributes set.UNTIL entry$<>index$(i-1) IF entry$=index$(i) =i ELSE =-i : : REM DO THE SEARCHING FOR FN_find_place : DEF FN_search(entry$) REPEAT IF entry$>index$(i) bottom=i ELSE top=i i=(top+bottom+1) DIV 2: REM round UNTIL entry$=index$(i) OR top=bottom+1 =i
Well, that's it. Apart from the following notes on the binary chop you have read it all.REM There are no 'native' clear to end of line/screen REM vdu procedures. The following 2 procedures clear to REM the end of the line/screen. : DEF PROC_cteol LOCAL x,y x=POS:y=VPOS REPEAT VDU 32 : UNTIL POS=0 PRINT TAB(x,y); ENDPROC : : DEF PROC_cteos LOCAL x,y x=POS:y=VPOS WHILE VPOS<24 VDU 32 : ENDWHILE REPEAT VDU 32 : UNTIL POS=0 PRINT TAB(x,y); ENDPROC
Let's try searching the list of numbers below for the number 14.
bottom> (1) 3 Set bottom to the lowest position in the list, and top to the highest. Set the pointer to (top+bottom)/2. Is that entry 14? No it's more, so set top to the current value of pointer and repeat the process. (2) 6 (3) 8 (4) 14 pointer> (5) 19 (6) 23 (7) 34 (8) 45 top> (9) 61
bottom> (1) 3 Set the pointer to (top+bottom)/2. Is that entry 14? No it's less, so set bottom to the current value of pointer and try again. (2) 6 pointer> (3) 8 (4) 14 top> (5) 19 (6) 23 (7) 34 (8) 45 (9) 61
As you can imagine, things are not always as simple as this carefully chosen example. You have to cater for the number not being there, and for the list being empty. There are a number of ways of doing this, but the easiest is to add two numbers of your choice to the list. Make the first entry the most negative number the computer can hold, and the last entry the most positive. This will prevent you ever trying to search outside the list. Preventing a perpetual loop when the number you want is not in the list is quite simple, just exit when 'top' is equal to 'bottom'+1. If you have not found the number by then, it's not in the list.
(1) 3 Set the pointer to (top+bottom)/2. Is that entry 14? Yes, so exit with the pointer set to the position in the list of the number you are looking for. (2) 6 bottom> (3) 8 pointer> (4) 14 top> (5) 19 (6) 23 (7) 34 (8) 45 (9) 61
You can use this routine to add numbers to the list in order. If you can't find the number, you exit with the position it should go in the list. Just move all the numbers under it down one slot and put the new number in. This works just as well when the list is empty except for your two 'end markers'.
Have a look at the flow chart below and work through a couple of dry runs with a short list of numbers. You may think that it's not worth doing it this way and that a 'linear search' would be as quick. Try it with a list of 100 numbers. It should take you no more than 7 goes to find the number. The AVERAGE number of comparisons required for a linear search would be 50.
|
CONTINUE
|