Unit selection speech synthesis systems, e.g. [1], have shown a significant improvement in output voice quality. Selecting appropriate sub-word units from large databases of natural speech has raised the level of speech synthesis to a quality, in its best case, equivalent to that of recorded speech. The quality is directly related to the implicit quality and style in the recorded databases, and at last the voice output sounds like the original speaker (though this has been said before).
Since the publication of a well defined selection algorithm for unit selection, [2], we have seen significant new work in acoustic measures, and in alternative algorithms for optimally finding the best set of units to join together (e.g. [3]). However in the search for better algorithms, we have also noted that better databases that cover the acoustic phonetic space of the language in question can also make significant contributions to the quality.
In [2], the notion of target cost for a candidate unit from a database with respect to the required unit is presented in the following formula.
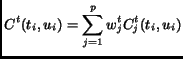
In addition units selected must not only have a small target cost but also join well. Join costs may be defined between two units as
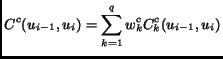
![$\displaystyle C(t_1^n, u_1^n) = \sum_{i=1}^n C^t(t_i, u_i) +
\sum_{i=2}^n C^c(u_{i-1},u_i) +
\makebox[5mm][0mm]{} $](img3.png)
Where
As highlighted in more detail in [4], the overall cost can be reduced in a number of ways, that do not just involved changing the acoustic measurements.
We can limit the set of utterances we wish to synthesize to those whose costs are low. [5] carries this to an extreme where the synthesizer defines a domain and will not synthesize outside that domain. However within domain, the quality can be very high, and for many applications this solution is ideal.
We can design the database itself to better cover the intended acoustic space, so that there are less possibilities for bad joins [6]. Appropriately designed databases are important for not just ``domain'' synthesizers but general synthesizers too, as they too, are designed to cover an intended (though larger) space.
Thus current unit selection can work well, when the desired utterances that must be synthesized are appropriate for the database they are to be selected from. It is notable that attaining variation outside that database is hard, and rarely even attempted as any form of signal processing to modify the spectral and prosodic quality of the speech, typically degrades the quality or at least makes it less natural.